What It Took To Make GitOps Image Pinning Actually Work
Most software engineering ideas sound cleaner in your head than they do once they collide with reality.
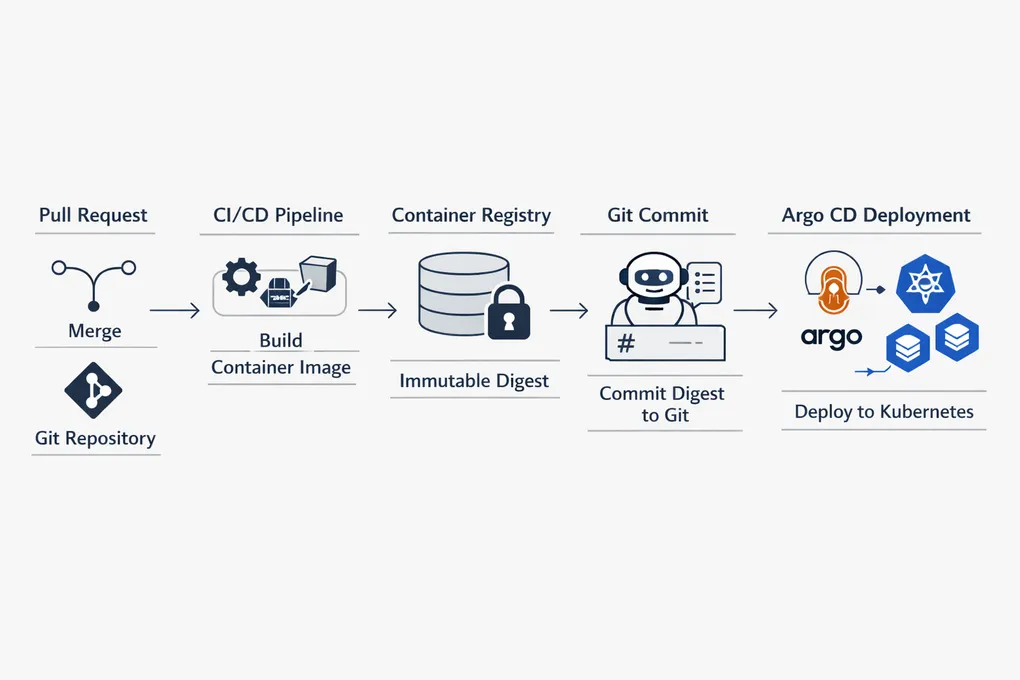
This one started with what felt like a very reasonable requirement: if I build a new container image for an application, I do not want my Kubernetes cluster pulling some mutable tag like latest. I want Git to declare the exact artifact that should run, and I want Argo CD to reconcile to that artifact and nothing else.
That means the flow has to look something like this:
- merge code to
main - build a new image in CI
- push it to a container registry
- capture the exact digest
- commit that digest back into Git
- let Argo CD deploy the pinned image
On paper, this is clean. In practice, it is a fascinating little knot of branch protection, automation identity, race conditions, and GitHub permission models.
The Goal Wasn’t “Fancy CI”
The point of the exercise was not to make the pipeline look more advanced. It was to preserve an important GitOps property: the cluster should deploy what Git says, not whatever image happens to be sitting behind a mutable tag.
That buys a few things immediately:
- deploys are deterministic
- rollbacks are deterministic
- the commit history tells you exactly what artifact was intended to run
- Argo CD remains the deployment mechanism rather than an observer of some other release process
This matters more than it first appears. If the image can change independently of Git, then the source of truth is no longer really Git. It is some blend of Git, registry state, timing, and luck.
Where It Got Interesting
The hard part was not Docker. The hard part was preserving all of the other constraints at the same time:
mainis protected and requires PRs- normal humans should not bypass that rule
- the image does not actually exist until after merge
- the artifact still needs to be recorded back into Git
- the automation identity should be narrow and auditable
- the final system should still be simple enough to trust
The first instinct was least privilege everywhere. I tried narrowing the automation down to a GitHub App that could only modify the two files involved in pinning the AI service image:
platform/ai-reliability/rollout.yamlplatform/ai-reliability/kustomization.yaml
Conceptually, that was beautiful.
Operationally, it turned into a tour of how platform permission models are often less elegant in motion than they appear in the UI.
GitHub App Permissions Were The Real Story
The GitHub App approach was still the right direction. It was much better than using a PAT or a deployment key:
- short-lived installation tokens
- repo-scoped installation
- a distinct automation identity
- cleaner auditability
- a ruleset bypass that was attached to one app instead of one human
But the last mile was more awkward than expected.
Some write paths behaved differently than others. Some helpers wanted the numeric App ID and not the client ID. Some permissions looked precise in the interface, but the behavior through Actions, the Git transport layer, and the Git database API did not line up as neatly as I wanted.
That turned into the most useful lesson of the whole experiment: least privilege is good, but there is a complexity cliff where the last bit of restriction costs you a disproportionate amount of engineering effort.
Eventually I landed on the pragmatic stopping point:
- use a GitHub App
- install it only on this repository
- give it repository
Contents: write - let only that app bypass the PR rule on
main - use it only for the post-merge image pin workflow
That is not the most theoretically minimal model. It is, however, a strong and supportable one.
Race Conditions Are Not Optional
The other subtle problem is timing.
If a workflow builds an image from commit A, but by the time it is ready to push the pinned digest back into Git the branch head has moved to commit B, then blindly pushing the digest risks pinning the wrong artifact onto newer source.
That is exactly the kind of mistake this workflow is supposed to prevent.
So the final workflow explicitly checks whether main advanced while the build was running. If it did, the pin step aborts instead of trying to be clever. That is a small check, but it is one of the most important reliability details in the whole design.
The Flow That Finally Worked
The final path looked like this:
- a PR merges into
main - GitHub Actions builds the AI service image and pushes it to GHCR
- the workflow captures the digest
- the workflow updates the rollout manifest to use the pinned digest
- the workflow commits that change back to
mainusing the GitHub App identity - Argo CD syncs the new digest into the cluster
That means the cluster ends up running an immutable artifact that is explicitly recorded in Git.
When I finally saw the digest appear in the rollout manifest and then verified that the running image in the cluster matched it, that was the moment the whole exercise stopped being theoretical.
Was It Worth It?
Yes, but with an asterisk.
It was worth it because it exposed a set of real engineering constraints that are easy to underestimate:
- GitOps is easy to describe and harder to preserve rigorously
- automation identity matters
- mutable tags are a footgun
- branch protection interacts with release automation in nontrivial ways
- platform permission models have real edges
It was also more machinery than most teams need.
If I were building this for many production teams, I would also seriously consider simpler paths:
- Argo CD Image Updater
- a dedicated promotion repository
- a repo-scoped bot with
Contents: write - a release-tag based promotion model
The point is not that every shop should build exactly this. The point is that if you care about immutable artifact promotion in a GitOps system, there is a real problem here to solve, and the “obvious” solution is rarely as simple as it first sounds.
The Real Takeaway
The most satisfying part of this project was not just that the idea worked. It was that the work surfaced the right tradeoff.
The final design is not “perfect least privilege.” It is:
- secure enough to be credible
- narrow enough to be responsible
- simple enough to be supportable
- explicit enough to preserve GitOps guarantees
That is usually the actual engineering target.