Trivy, Smoke Tests, and the Kind of Supply Chain Lesson You Only Learn By Doing
One of my favorite things about infrastructure work is that sometimes you add a tool for one reason and it immediately proves its value for a different reason.
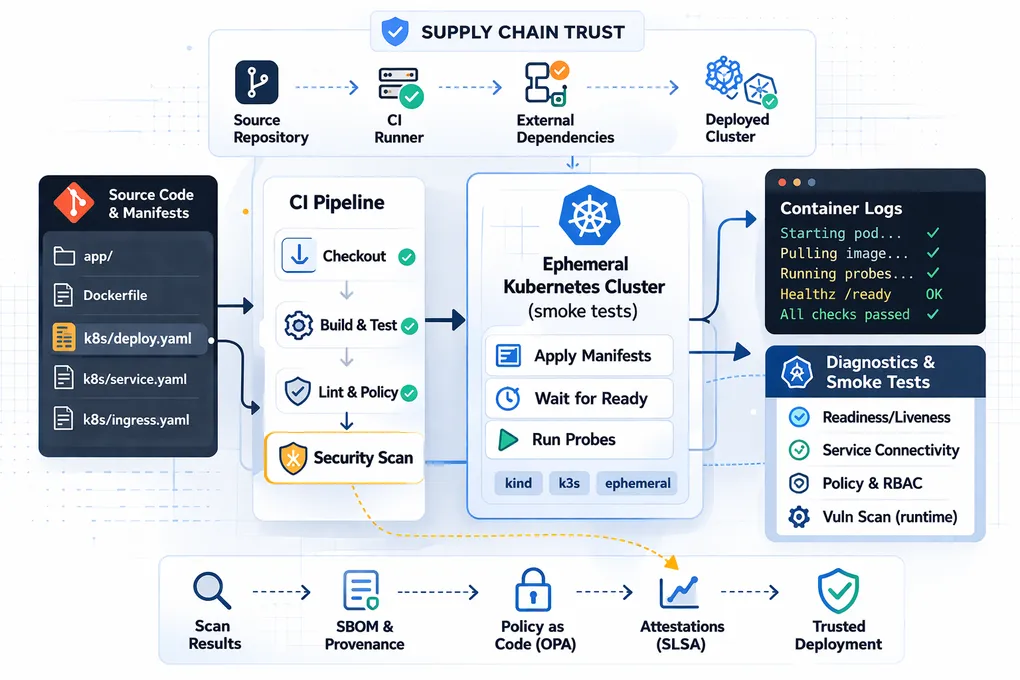
That is basically what happened when I added Trivy scanning and deployment smoke tests to a small GitOps lab.
At first glance, this sounds like ordinary CI hygiene:
- lint the manifests
- render the Helm chart
- validate the YAML
- run a security scan
- deploy into a disposable cluster
That all sounds sensible but routine. What made it interesting was what the tools actually surfaced once they were in place.
Trivy Didn’t Just Add Noise
The first useful surprise was that Trivy immediately found security hardening gaps in manifests that were otherwise “working.”
The issues were not especially exotic:
- default security contexts
- writable root filesystems
- missing explicit pod-level security settings
This is exactly why static security tooling is useful in Kubernetes repositories. A manifest can be functionally correct and still carry a lot of security debt.
In a small lab, it is very easy to say “good enough, it deploys.” The problem is that defaults are often more permissive than people realize, and those permissive defaults have a way of surviving longer than they should.
The valuable part was that the scan forced real improvements:
- explicit
securityContext runAsNonRootreadOnlyRootFilesystemseccompProfile: RuntimeDefault- writable paths only where the runtime actually needed them
That is a much better outcome than simply having a green pipeline.
The Smoke Test Was Even Better
The second surprise was that hardening the manifests introduced a real deployability bug that the static checks did not catch.
The issue was subtle:
- a workload was hardened with
readOnlyRootFilesystem: true - writable runtime paths were mounted only under a certain feature toggle
- the CI smoke path deliberately disabled that feature
- the application could no longer boot correctly under the CI combination
So the manifests were valid. The security scan was happy. The workload still failed to become ready.
That is the exact kind of problem smoke tests are meant to catch.
This is where the pairing becomes powerful:
- Trivy says the manifest is not hardened enough
- the smoke test says your hardening still has to produce a bootable application
That is a much more meaningful quality bar than linting alone.
The Hidden Lesson Was Diagnostics
The first version of the smoke test failed in the least useful possible way: it timed out.
That is technically information, but not enough to operate on.
A timeout without context leaves you rebuilding the same mental model over and over:
- is the scheduler stuck?
- is the container crashing?
- did the security context break startup?
- are the service endpoints empty?
- is readiness wrong?
So the CI job got better. It started collecting:
- pod state
- deployment status
describeoutput- recent logs
- service and endpoint information
That made the smoke test feel less like a gate and more like an operator assist. In practice, that distinction matters a lot. A red check with no context is a tax. A red check with useful forensics is part of the system.
Then the Supply Chain Question Arrived
Around the same time, the security conversation widened in a way that felt almost unfairly on-theme: the CI scanner itself became part of the trust discussion.
Originally, I had looked at using the hosted trivy-action GitHub Action directly. That later became a much more interesting decision in light of the broader industry concern around compromised CI dependencies and action trust.
The immediate takeaway was not “never use third-party actions.” It was more nuanced:
- using a GitHub Action means trusting more than just the tool
- installing the CLI directly removes one layer of workflow indirection
- but runtime installs still trust upstream distribution and installer infrastructure
- pinning versions improves reproducibility but slows update intake
- following
latestimproves freshness but increases exposure to bad upstream changes
There is no magic answer here. There is only tradeoff management.
That is one of the reasons I think supply chain security belongs in reliability conversations, not just security reviews. If your CI system is part of your release path, its trust model is an operational concern.
What This Small Lab Ended Up Proving
This started as a demo repository. It ended up proving a few things I think are broadly useful:
- Security scanning is valuable even in a toy environment because bad defaults do not stop being bad just because the repo is small.
- Runtime validation matters because structurally valid Kubernetes does not guarantee a bootable workload.
- Diagnostics are almost as important as pass/fail status if you want CI to reduce time to diagnosis.
- Supply chain trust is part of CI design, not an afterthought.
That is a pretty good return from what looked, initially, like just “add Trivy and a smoke test.”
The Broader Takeaway
The most useful pattern here is not any single tool. It is the layering:
- static analysis for baseline mistakes
- runtime smoke tests for deployability
- useful diagnostics for failure handling
- explicit thinking about what your pipeline itself is trusting
That stack gets you much closer to real platform discipline than a repo that only proves YAML can render.